计算机网络 Lab4 路由协议
libpcap 库
libpcap 的整体执行流程如下:
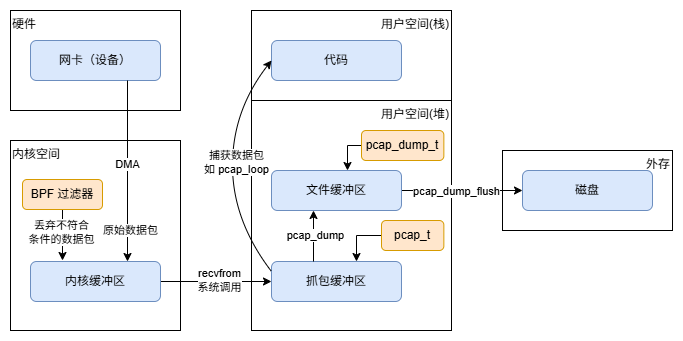
核心数据结构
-
会话句柄
typedef struct pcap pcap_t; // 捕获会话句柄(不透明结构) typedef struct pcap_dumper pcap_dumper_t; // 转储文件句柄注:句柄可以类比函数指针,但是不完全相同。函数指针是内存地址,可以直接调用;句柄只是一个对象的标识,只能传入接口函数由其内部调用,实际上它可能是函数指针也可能仅仅是一个整数标识符。
-
数据包头部
struct pcap_pkthdr { struct timeval ts; /* 时间戳(捕获时间) */ bpf_u_int32 caplen; /* 实际捕获的数据长度(可能截断) */ bpf_u_int32 len; /* 数据包原始长度 */ };其中:
#include <sys/time.h> struct timeval { time_t tv_sec; // 秒数(从 1970-01-01 00:00:00 UTC 开始) suseconds_t tv_usec; // 微秒数(0-999999) };注:
caplenlen,当设置 snaplen 截断捕获时,两者可能不等。 -
回调函数
在抓到包后调用,按用户自定义的方式处理数据包。
typedef void (*pcap_handler)(u_char *user, const struct pcap_pkthdr *h, const u_char *bytes);user:用户自定义数据h:libpcap 提供的数据包的头部bytes:libpcap 提供的数据包的实际内容(以太网帧开始)
-
BPF 过滤器程序
伯克利数据包过滤器(Berkeley Packet Filter)。
struct bpf_program { u_int bf_len; /* 指令数量 */ struct bpf_insn *bf_insns;/* 指向过滤指令数组的指针 */ }; -
网络设备信息
typedef struct pcap_if { struct pcap_if *next; /* 下一个设备 */ char *name; /* 设备名(如 "eth0") */ char *description; /* 设备描述 */ struct pcap_addr *addresses; /* 地址列表 */ u_int flags; /* 标志(PCAP_IF_LOOPBACK等) */ } pcap_if_t; -
统计信息
struct pcap_stat { u_int ps_recv; /* 收到的包数 */ u_int ps_drop; /* 丢弃的包数(缓冲区满) */ u_int ps_ifdrop; /* 接口层丢弃的包数 */ };
核心函数接口
-
设备查找与打开
由于 PC 上有多个网卡(设备),比如有线网卡
wth0、无线网卡wlan0、回环网卡lo,所以我们必须指定捕获设备。获取设备信息:
函数原型 功能说明 char *pcap_lookupdev(char *errbuf)返回第一个可用的非回环设备名(已废弃,建议用 pcap_findalldevs)int pcap_findalldevs(pcap_if_t **alldevsp, char *errbuf)获取所有可用网络设备列表, alldevsp是一个在堆上的链表void pcap_freealldevs(pcap_if_t *alldevs)释放设备列表,也即释放堆上分配的内存 int pcap_lookupnet(const char *device, bpf_u_int32 *netp, bpf_u_int32 *maskp, char *errbuf)获取设备的网络地址和掩码 打开实时捕获设备:
pcap_t *pcap_open_live(const char *device, int snaplen, int promisc, int to_ms, char *errbuf);snaplen: 最大捕获字节数(通常设 65535 或 BUFSIZ)。promisc: 1 开启混杂模式,0 非混杂。混杂模式下会接收所有经过设备的数据包。to_ms: 读取超时(毫秒),0 表示无超时阻塞等待。
离线操作:
// 打开一个之前保存的抓包文件 pcap_t *pcap_open_offline(const char *fname, char *errbuf); // 创建虚拟句柄(用于编译 BPF 过滤器) pcap_t *pcap_open_dead(int linktype, int snaplen); -
数据包捕获
函数原型 功能说明 int pcap_loop(pcap_t *p, int cnt, pcap_handler callback, u_char *user)循环捕获 cnt个包(-1 表示无限),每次捕获调用callbackint pcap_dispatch(pcap_t *p, int cnt, pcap_handler callback, u_char *user)类似 loop,但超时或处理完缓冲区内数据即返回 const u_char *pcap_next(pcap_t *p, struct pcap_pkthdr *h)捕获单个数据包,阻塞等待,返回指向原始数据包的指针 int pcap_next_ex(pcap_t *p, struct pcap_pkthdr **pkt_header, const u_char **pkt_data)捕获单个包(返回 1:成功,0:超时,-1:错误,-2:离线文件EOF)void pcap_breakloop(pcap_t *p)中断正在运行的 pcap_loop/dispatch -
数据包过滤
// 编译过滤表达式 int pcap_compile(pcap_t *p, struct bpf_program *fp, char *str, int optimize, bpf_u_int32 netmask); // 应用过滤器 int pcap_setfilter(pcap_t *p, struct bpf_program *fp); // 释放编译后的 BPF 程序内存 void pcap_freecode(struct bpf_program *fp);p:提供编译所需的链路层类型、快照长度。fp:是输出参数,编译生成的 BPF 指令会存储在这里。str:人类可读的过滤表达式字符串,例如"tcp port 80"或"host 192.168.1.1"。optimize:是否优化生成的 BPF 指令,1表示优化,0表示不优化。netmask:网络掩码,用于解析net/mask这类过滤器;不需要时可传PCAP_NETMASK_UNKNOWN(通常就是0)。
示例流程:
pcap_t *handle = pcap_open_live("eth0", 65535, 1, 1000, errbuf); struct bpf_program fp; pcap_compile(handle, &fp, "icmp or tcp port 80", 1, net); pcap_setfilter(handle, &fp); pcap_freecode(&fp); -
数据包转储
// 打开转储文件 pcap_dumper_t *pcap_dump_open(pcap_t *p, const char *fname); pcap_dumper_t *pcap_dump_fopen(pcap_t *p, FILE *fp); // 写入数据包(可作为 pcap_loop 的回调函数) void pcap_dump(u_char *user, struct pcap_pkthdr *h, u_char *sp); // 刷新缓冲区到磁盘 int pcap_dump_flush(pcap_dumper_t *p); // 关闭转储文件 void pcap_dump_close(pcap_dumper_t *p);注:
-
辅助与清理函数
函数 说明 int pcap_datalink(pcap_t *p)获取链路层类型(如 Ethernet 为 1) int pcap_snapshot(pcap_t *p)获取 snaplen int pcap_stats(pcap_t *p, struct pcap_stat *ps)获取捕获统计 char *pcap_geterr(pcap_t *p)获取错误信息 void pcap_perror(pcap_t *p, char *prefix)打印错误信息 void pcap_close(pcap_t *p)关闭会话并释放资源
典型使用流程
char errbuf[PCAP_ERRBUF_SIZE];
pcap_if_t *alldevs;
pcap_t *handle;
struct bpf_program fp;
// 1. 查找设备
pcap_findalldevs(&alldevs, errbuf);
// 2. 打开设备
handle = pcap_open_live(alldevs->name, 65535, 1, 1000, errbuf);
// 3. 编译并设置过滤器
pcap_compile(handle, &fp, "port 80", 0, PCAP_NETMASK_UNKNOWN);
pcap_setfilter(handle, &fp);
// 4. 循环捕获
pcap_loop(handle, 0, packet_handler, NULL);
// 5. 清理
pcap_freecode(&fp);
pcap_close(handle);
pcap_freealldevs(alldevs);参考文档:
lab 中的重要数据结构与函数
协议头部
// Ethernet frame header
typedef struct {
uint8_t dst_mac[6]; // Destination MAC address
uint8_t src_mac[6]; // Source MAC address
uint16_t ether_type; // Ethernet type (e.g. 0x0800 for IP)
} __attribute__((packed)) eth_header_t;
// IP protocol header
typedef struct {
uint8_t version_ihl; // Version (4 bits) + IHL (4 bits)
uint8_t tos; // Type of service
uint16_t total_len; // Total length
uint16_t id; // Identification
uint16_t frag_off; // Flags (3 bits) + Fragment offset (13 bits)
uint8_t ttl; // Time to live
uint8_t protocol; // Protocol (TCP=6, UDP=17)
uint16_t checksum; // Header checksum
uint32_t src_ip; // Source IP address
uint32_t dst_ip; // Destination IP address
} __attribute__((packed)) ip_header_t;网络设备有关数据结构
我们先区分一下 device 的概念。 下面所有的 device 均指网卡 NIC / 端口 port,而使用 node 指代网络中的物理设备节点(如 Hub、Switch、Router、Host)。
device 类型 net_device_t 中存储了网卡的名称、索引以及捕获线程信息。实际上还应储存网卡的 MAC,由于缺失导致 Router 实现会有问题。
node 内有 packet buffer 用于储存收到的 packet。
packet 的条目类型为 packet_entry_t,储存了 packet 的入端口(ingress device)、原始数据、真实数据长度以及收包时间。
而整个 packet buffer 类型 packet_buffer_t 则是一个环形队列,为了并行添加了信号量进行保护。
可以在 setup_star.sh 中看到拓扑网络的详细信息。
其中定义了 node device、host1、host2、host3、host4(注意这里的 device 是指物理设备)。
每个 node 添加了 device node/hostx-ethx。
/* Network device information */
typedef struct {
char name[32]; // Device name
pcap_t *handle; // pcap handle
pthread_t thread_id; // Capture thread ID
int index; // Device index
} net_device_t;
/* Packet buffer entry */
typedef struct {
net_device_t *device; // Ingress device
uint8_t data[PACKET_BUF_SIZE]; // Packet data
uint32_t len; // Packet length
uint64_t timestamp; // Capture timestamp
} packet_entry_t;
/* Global packet buffer */
typedef struct {
packet_entry_t packets[MAX_PACKETS];
int head;
int tail; // circular buffer
pthread_mutex_t lock; // mutex lock
} packet_buffer_t;在 lab.c 中实例化。
devices 储存所有 node 的所有我们自己创建的 device,也即名为 device/hostx-ethx。注意每个 node 会有一些 Docker 默认 device,比如 eth0、lo 等。
由于只模拟一台物理设备 Hub/Switch/Router,所以只实例化了它内部的一个 packet_buffer。
net_device_t devices[MAX_DEVICES];
int device_count = 0;
packet_buffer_t pkt_buffer;send_packet
发送数据包的函数。
dev 指明了 node 发包的出端口(egress device),data 和 len 为原始数据与长度。
int send_packet(net_device_t *dev, const uint8_t *data, uint32_t len) {
if (pcap_inject(dev->handle, data, len) == -1) {
fprintf(stderr, "Error sending packet on %s: %s\n",
dev->name, pcap_geterr(dev->handle));
return -1;
}
return 0;
}capture_thread
接收数据包的线程函数。
注意传入的参数为收包设备的指针 net_device_t*。
void *capture_thread(void *arg) {
net_device_t *dev = (net_device_t *)arg;
struct pcap_pkthdr header;
const u_char *packet;
printf("Starting capture on %s\n", dev->name);
while (1) {
packet = pcap_next(dev->handle, &header);
printf("pcap_next returned on %s: %p\n", dev->name, packet);
if (!packet)
continue;
pthread_mutex_lock(&pkt_buffer.lock);
// Check if buffer is full
if ((pkt_buffer.head + 1) % MAX_PACKETS == pkt_buffer.tail) {
fprintf(stderr, "Packet buffer full, dropping packet\n");
pthread_mutex_unlock(&pkt_buffer.lock);
continue;
}
// Store packet in buffer
packet_entry_t *entry = &pkt_buffer.packets[pkt_buffer.head];
entry->device = dev;
entry->len = header.len;
entry->timestamp = header.ts.tv_sec * 1000000 + header.ts.tv_usec;
memcpy(entry->data, packet, header.len > PACKET_BUF_SIZE ? PACKET_BUF_SIZE : header.len);
pkt_buffer.head = (pkt_buffer.head + 1) % MAX_PACKETS;
pthread_mutex_unlock(&pkt_buffer.lock);
}
return NULL;
}common_init
主要进行了以下工作:
- 初始化 node 内的环形队列 packet buffer。
- 寻找网络设备。
- 筛选并储存我们自己创建的 device,也即名为
device/hostx-ethx。 - 为筛选后的 device 创建 pcap 捕获会话句柄,并为其创建对应的线程持续收发数据包。
Hub
Hub 位于物理层,直接无条件泛洪收到的包。
for (int i = 0; i < device_count; i++) {
// 因为 entry->device 存储的是 devices 数组中的地址,所以可以直接比较指针
// if (&devices[i] == entry->device) {
// continue;
// }
// 也可以比较设备名
if (strcmp(devices[i].name, entry->device->name) == 0) {
continue;
}
send_packet(&devices[i], entry->data, entry->len);
}在 setup_star.sh 中的指令:
sudo docker exec $container1 ip link set $veth1 up
sudo docker exec $container2 ip link set $veth2 up打开网络接口,接口默认启用 IPv6,所以会自动在链路上探测 IPv6 路由器,持续探测一段时间才会暂停。
而 test_hub 执行过早就会接收到这些 IPv6 包。不过只要在 setup_star.sh 一段时间之后再 test_hub 就不会收到了。
Makefile 的 test_hub 增加 sleep 1,保证避免过快 killall 导致 ping reply 没有记录。
Switch
Switch 位于链路层,内部存有 MAC 学习表。
学习表的条目类型 fdb_entry_t 储存 MAC 与 Switch 的端口 device 的对应关系。整个学习表类型 forwarding_db_t 为一个数组。
/* MAC address to device mapping entry */
typedef struct {
uint8_t mac[6]; // MAC address
char device[32]; // Device name
} fdb_entry_t;
/* Forwarding database (MAC learning table) */
typedef struct {
fdb_entry_t entries[MAX_DEVICES];
int count;
} forwarding_db_t;Switch 在一个端口 device 接收到数据包时,会先利用包的 Ether 头部中的 src MAC 字段学习到对应关系 <src MAC, device>。
然后根据 dst MAC 进行转发,此时需要查询学习表。若已有条目则直接转发,否则进行泛洪。
// Get Ethernet header
eth_header_t *entry_eth = (eth_header_t *)entry->data;
// Learn source MAC address
int found = 0;
// Found mac entry, update the corresponding device
for (int i = 0; i < fdb.count; i++) {
if (memcmp(fdb.entries[i].mac, entry_eth->src_mac, 6) == 0) {
found = 1;
memcpy(fdb.entries[i].device, entry->device, 31);
break;
}
}
// Otherwise add the learning entry
if (!found) {
memcpy(fdb.entries[fdb.count].mac, entry_eth->src_mac, 6);
memcpy(fdb.entries[fdb.count].device, entry->device, 31);
fdb.count++;
}
// Forward packet
found = 0;
// case 1: Found destination, forward to that device
for (int i = 0; i < fdb.count; i++) {
if (memcmp(fdb.entries[i].mac, entry_eth->dst_mac, 6) == 0) {
found = 1;
// Found device info by mac
for (int j = 0; j < device_count; j++) {
if (strcmp(devices[j].name, fdb.entries[i].device) == 0) {
send_packet(&devices[j], entry->data, entry->len);
break;
}
}
break;
}
}
// case 2: Flood to all ports except ingress
if (!found) {
for (int i = 0; i < device_count; i++) {
if (&devices[i] == entry->device)
continue;
send_packet(&devices[i], entry->data, entry->len);
}
}不过由于 fdb_entry_t 中储存的不是设备指针而只有设备名,所以每次都必须在所有设备中用设备名进行查询。
Router
Router 位于网络层,内部存有路由表。 Router 依据路由表决定包的转发路径,其匹配粒度为网络前缀(而非单个主机)。查表时遵循 Longest Prefix Match 原则。 Router 转发时只负责送到下一跳(next-hop):下一跳可能是目标子网内的某台主机(直接交付),也可能是另一台 Router(间接交付)。
子网是一组可以不经过路由器直接通信的 IP 地址集合,由网络地址和子网掩码共同定义。
Router 分为 Data Plane 和 Control Plane,二者在功能上分离:
- Control Plane:运行路由协议,处理协议报文,维护并更新路由表。
- Data Plane:依据已建立的路由表,对收到的 IP 数据包执行实际的转发、头部修改与重封装。
在该实验框架中,两个 plane 各使用一个 buffer:
- Data Plane 使用上述
packet_buffer_t类型的 pkt_buffer。 - Control Plane 使用
cp_buffer_t类型的 cp_buffer,结构与 pkt_buffer 完全相同。
路由表与距离向量
路由表条目类型 route_entry_t 储存 egress device 与对应的 network IP、子网掩码以及距离。
整个路由表类型 routing_table_t 以数组存储。
距离向量包类型 dv_packet_t 用于邻居间交换路由更新,包含自身 network IP、子网掩码以及距离。注意所有的 dv_packet 都是大端序的。
/* Routing table entry */
typedef struct {
uint32_t dest_ip; // Destination IP address
uint32_t mask; // Network mask
char out_dev[32]; // Output device name
uint32_t distance; // Distance metric
} route_entry_t;
/* Distance Vector (DV) packet */
typedef struct {
uint32_t dest_ip; // Destination IP address
uint32_t mask; // Network mask
uint32_t distance; // Distance metric
} __attribute__((packed)) dv_packet_t;
/* Routing table */
typedef struct {
route_entry_t entries[MAX_ROUTES];
int count;
} routing_table_t;
/* Control plane message buffer */
typedef struct {
packet_entry_t packets[MAX_PACKETS];
int head;
int tail;
pthread_mutex_t lock;
} cp_buffer_t;转发时的头部处理
Router 作为三层设备,在出端口转发前必须对二层和三层头部进行必要的修改与重封装:
- TTL 减 1:若 TTL 降为 0,则丢弃该包并返回 ICMP Time Exceeded(实验实现中可选择丢弃)。
- 重新计算 IP Header Checksum:因 TTL 字段变化,必须重新计算校验和。
- 重写以太网帧头:
src_mac设为出端口(egress device)自身的 MAC 地址;dst_mac设为下一跳设备的 MAC 地址(通过 ARP 或静态映射获得)。
正因如此,net_device_t 中必须存储各网卡自身的 MAC 地址;若缺失,Router 将无法正确填写以太网帧的源地址,导致转发异常。
routing table 的互斥锁
lab 中没有,实际上需要添加。