DCQCN 研读
论文一览
- 论文标题:Congestion Control for Large-Scale RDMA Deployments[大规模 RDMA 部署的拥塞控制]。
- 作者与会议信息:Yibo Zhu 等,SIGCOMM ’15(2015)。
- 研究领域:数据中心传输(datacenter transport)、RDMA(Remote Direct Memory Access)、PFC/ECN/网络拥塞控制。
- 主要贡献:
核心是对 switch 出口队列的拥塞进行端到端的控制。
- 在 NIC 上设计并实现了面向 RoCEv2 的端到端速率式拥塞控制,即 DCQCN;
- 基于流体模型给出参数调优与交换机缓冲阈值设置指南;
- 在 3 层 Clos 测试床与实际 NIC 上验证,显著提升吞吐与公平性并减少 PFC 级联影响。
注:区分窗口式与速率式的拥塞控制。
| 对比维度 | Window-based | Rate-based |
|---|---|---|
| 核心控制变量 | cwnd(拥塞窗口,单位:包数 / 字节数) | R_C(当前发送速率,单位:bps) |
| 实际发送速率 | 速率 ≈ cwnd / RTT | 速率 = R_C |
| 发包模式 | 受 ACK 时钟驱动,天然突发式 (bursty) | 可被硬件限速器平滑为均匀/pacing 发送 |
| 反馈信号 | ACK 中的 ECE / 丢包 / 延迟 | CNP(拥塞通知包)、RTT 变化、显式反馈 |
| 典型协议 | TCP, DCTCP, TCP-Bolt, CUBIC | DCQCN, QCN, TIMELY, HPCC |
| 实现位置 | 通常在内核或软件协议栈 | 需要 NIC 硬件支持(速率器、定时器) |
| 对 RTT 依赖 | 强依赖:速率估算需 RTT | 弱依赖:速率本身不依赖 RTT,但反馈延迟仍影响响应速度 |
| 多流公平性收敛 | 靠 AIMD 窗口调整实现,收敛较成熟 | 需要算法设计(如 DCQCN 的字节计数器 + 定时器) |
| 队列振荡 | 由于突发发送,容易造成队列抖动 | 平滑发送有利于降低队列抖动 |
| 典型部署场景 | 通用互联网、数据中心 TCP | 高性能数据中心 RDMA(RoCEv2)、低延迟网络 |
背景知识
RDMA
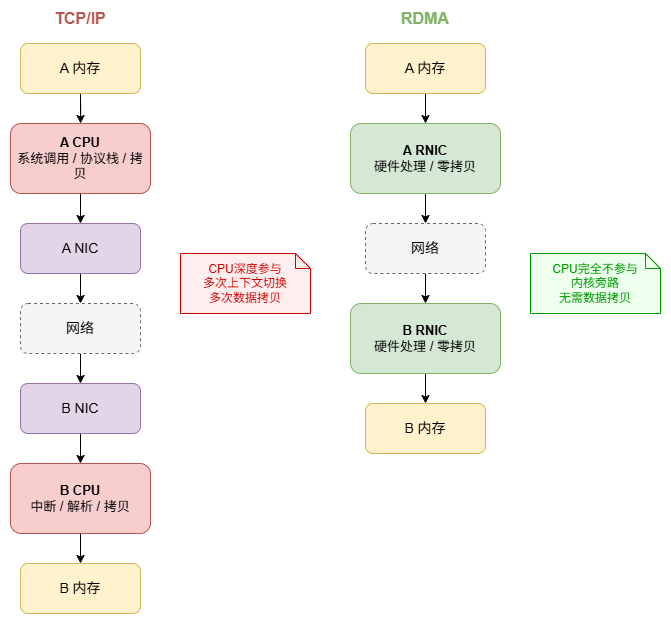
远程直接内存访问(Remote Direct Memory Access)。
允许应用程序在用户态直接驱动 RNIC(RDMA NIC),绕过 CPU 和操作系统内核,直接与对端内存进行 DMA 数据传输。
RoCE
融合以太网上的 RDMA(RDMA over Converged Ethernet)。
这是在 Ether 上实现 RDMA 的方案。
核心概念
PFC
优先级流控(Priority-based Flow Control, PFC)。
定义:一种以太网链路层机制,通过发送 PAUSE/RESUME 控制帧在端口或优先级粒度阻止上游发送以避免丢包(lossless 假设)。
核心思想:在队列超过阈值时立即向上游发送 PAUSE,直到队列下降到 RESUME 阈值,从而实现无丢包转发。
背景与目的: RoCEv2 需要无丢包 L2 环境以实现低延迟 RDMA, 但 PFC 的粗粒度(端口/优先级)会引发拥塞传播(congestion-spreading)、头阻(head-of-line)和不公平问题(如 parking lot 与受害流)。 DCQCN 的目标是配合 PFC 以减少其副作用(不同于完全去掉 PFC)。
关键限制/假设:依赖交换机和 NIC 支持 PFC,且 PFC 本身会在多跳产生级联 PAUSE;需要结合流级拥塞控制以避免频繁触发 PFC。
💡 常见疑问与解答(PFC)
- Q:若完全禁用 PFC 会怎样? A:DCQCN 无慢启动,流起始以线速发送,若无 PFC 在瞬态会发生丢包并严重降速(实现退化),论文测试表明没有 PFC 会导致部分流无法恢复(10th 百分位为 0)。
ECN/RED
显式拥塞通知(Explicit Congestion Notification)与随机早期检测(Random Early Detection)。
定义:在出口队列超过阈值时基于 RED 算法概率或截断式(cut-off)将 IP 包标记为 ECN,以向端点反馈网络拥塞信息。
核心思想: 通过在交换机处打 CE(拥塞暴露)标记并由接收端生成 CNP(Congestion Notification Packet)回馈给发送端,实现端到端流的速率调节。 DCQCN 既支持 DCTCP 风格的 Kmin=Kmax(cut-off)也支持 RED-like(Kmin<Kmax,Pmax>0)以改善多瓶颈或速率差异场景。
数学表达(标记概率 p):论文给出的 RED-ECN 行为(式 (5)):
符号说明:q(t) 出口队列长度,K_min/K_max 标记区间,P_max 最大标记概率。
适用场景:需要细粒度流级控制且交换机支持 RED/ECN 的数据中心网络。
关键限制/假设:RED 参数须与 RP 的 CNP 生成节律配合,否则大流可能产生不良收敛(见参数调优)。
💡 常见疑问与解答(ECN/RED)
- Q:在多瓶颈情况下为何用 RED 比 cut-off 更好? A:RED 的概率标记使得在计时驱动的 CNP 生成下,大流更可能被频繁标记并更快回退,缓解多瓶颈不公平问题(论文实验与模型均支持)。[来源:DCQCN.pdf,第 8、12 页]
DCQCN 算法(RP/CP/NP)
DCQCN(Datacenter QCN)
Switch 探测到拥塞 → 打 CE 标记 → NP(接收端)收到后发 CNP → RP(发送端)收到 CNP 后降速。
定义:一种面向 RoCEv2 的端到端速率式(rate-based) 拥塞控制方案,在 NIC 上实现发送端(RP,reaction point)与接收端(NP,notification point),交换机为拥塞点(CP)负责 ECN 标记。
核心思想:结合交换机端 ECN 标记 + 接收端 CNP 汇报 + 发送端速率控制(无慢启动、即时线速开始、基于 α 的速率削减与基于计时/字节计数的增益恢复),用 PFC 做“最后一刻”的防丢保护,从而实现快速响应与长期稳定。
背景与目的:解决 RoCEv2 部署中 PFC 引发的不公平与拥塞蔓延问题,同时满足低 CPU 开销与超快启动需求(相比 DCTCP/QCN/iWarp)。
算法拆解:
- CP(交换机,Egress)
- 输入:到达数据包、队列长度 q。
- 操作:根据 RED/ECN(Kmin,Kmax,Pmax)决定是否在包上置 CE 位。目的:在出口点检测拥塞并向流回报。
- NP(接收端,Notification Point) — 状态机(Figure 6)
- 输入:到达的 CE 标记包(属于某流);时间参数 N(论文用 N=50μs)。
- 操作:若最近 N μs 内无 CNP,为该流立即发送一条 CNP;随后每 N μs 最多发一条 CNP(若期间有 CE 包)。目的:以可控频率把 CE 通知回发送端,降低 NIC 处理开销。
- RP(发送端,Reaction Point) — 伪码/状态(见 Figure 7,公式 (1)-(4))
- 输入:收到 CNP(携带流标识);本流当前速率 R_C、目标速率 R_T、alpha α、参数 g。
- 操作(收到 CNP 时):
- 记录目标速率 R_T ← R_C;当前速率 R_C ← R_C*(1 − α/2);更新 α ← (1−g)α + g。 (式 (1))
- 若在无反馈 K 时间内(K=55μs)无 CNP 到达,按 α ← (1−g)α 衰减(式 (2))。
- 恢复/增速由字节计数(每 B 字节)和定时器 T 驱动(快速恢复 F 步:R_C ← (R_T + R_C)/2;之后按 R_AI 逐步提升 R_T;参见式 (3) 与 (4))。目的:快速削减并受控恢复速率,兼顾响应性与稳定性。
- 输出:新的发送速率 R_C、更新的 α 与 R_T。 [来源:DCQCN.pdf,第 5–6 页]
💡 常见疑问与解答(DCQCN 算法)
- Q:为何不采用窗口式(window-based)而选速率式?
A:速率式便于 NIC 硬件实现并提供更细粒度的速率限制;窗口式在 NIC 上实现复杂且粗糙。 [来源:DCQCN.pdf,第 6 页] - Q:CNP 频率为何设为 N=50μs?如何迁移到不同 RTT?
A:50μs 受 NIC 硬件 CNP 生成能力限制。若 RTT 更长,应相应增大 RP 的 K 与定时器,使得 RP 不会在 CNP 间隙误增速;流体模型用于指导这些调整(见 §5)。[来源:DCQCN.pdf,第 5、8 页]
公式与流体模型
- 论文主要流体模型(式 (5)-(9),表示 DCQCN 在单瓶颈下的动态):
符号说明见论文表格(摘要)并复述关键项:R_C(当前速率),R_T(目标速率),α(削减因子),q(队列),N(流数),C(瓶颈带宽),g(α 更新权重),τ*(反馈延迟, 包含 RTT 与 CNP 生成),K_min/K_max/P_max(RED 参数)。
直观理解:队列由 N 个流的速率与链路容量差驱动;ECN 标记概率 p 影响 α 的演化与 R_C 的削减;参数 g 控制 α 收敛速度与系统振荡幅度(g 小 → 更稳定但收敛慢)。固定点为 R_C = C/N(式 (10)),表示公平分配。
简要推导:
- 假设 N 个贪婪流共享单瓶颈 C,写出队列动态 dq/dt = ΣR_C − C。
- 根据 RED 给出 p(q)(式 (5));p 驱动 NP 生成 CNP 的概率/频率。
- 模型 RP 收到延迟 τ* 后按式 (1)-(4) 做 α 更新与速率调整,写出 R_C、R_T 的微分方程(式 (8),(9))。
- 求稳态(设导数为 0)得到固定点 R_C = C/N,联立得到 p、α、R_T 的稳态值。
- 用数值解(论文用)评估参数敏感性,选择收敛快且队列小波动的参数集(见下)。 需要验证点:反馈延迟 τ* 在你的网络是否≈50μs(论文默认),否则 K、Timer、ByteCounter 需重算与仿真验证。
参数与关键参数表:
- 推荐值(论文收敛与部署结论):Timer = 55 μs;Byte Counter B = 10 MB;K_max = 200 KB;K_min = 5 KB;P_max = 1%;g = 1/256;CNP interval N = 50 μs;R_AI = 40 Mbps;F = 5。
- 说明/实验影响:
- 将 Timer 设为 55 μs(略大于 CNP 生成间隔 50 μs)可加速速率增加而避免在 CNP 之间误增速;ByteCounter 设大(10MB)防止过早触发 hyper increase;K_max=200KB 与 P_max=1% 采用 RED-like 标记以改善多瓶颈公平性;g=1/256 可减少队列波动(图 12 显示 g 越小队列越稳定)。
实验与评估:
- 测试拓扑:三层 Clos(4 ToR、4 Leaf、2 Spine),所有链路 40Gbps,交换机 Arista 7050QX32(Trident II)。图示在论文 Figure 2。
- 关键配置:交换机启用 PFC、RED-ECN(K_min/K_max/P_max 依据上表),NIC 实现 RP/NP 状态机,CNP 优先级高。
- 评估指标:吞吐(median/10th percentile)、公平性、队列长度(延迟的代理)、PFC PAUSE 消息总数、对受害流/parking-lot 情形的影响。
- 主要结果(要点):
- 吞吐与公平性:在“parking lot”与 victim-flow 场景,启用 DCQCN 后多个流公平分享瓶颈,消除了 H4 优势与受害流吞吐下降(对比 Fig.3/4 vs Fig.8/9)。
- 抗冲击性:在含 incast 的 benchmark(用户流 + 磁盘重建流)中,DCQCN 显著提高用户流 median 与 10th 百分位吞吐,并降低 spine 上 PAUSE 消息数(从百万级降到千级,见 Figure 15)。
- 延迟/队列:与 DCTCP 相比,DCQCN 的 egress 队列更浅(95%-tile:76.6KB vs 162.9KB),意味着更低的排队延迟。
- 小结表(定量摘录):
- PAUSE 消息数:无 DCQCN: ~6e6;有 DCQCN:~3e3(示例数字见 Figure15)。
- 10th 百分位 incast 吞吐(incast=10):无 DCQCN 约 1.12 Gbps;有 DCQCN 约 3.43 Gbps(Figure 16)。
对比与启发
- DCQCN vs DCTCP vs QCN vs TIMELY(摘要对比):
- DCQCN:优点——为 RoCEv2 设计,NIC 实现,速率式,配合 PFC;缺点——依赖 PFC 与硬件 CNP 限制;适用——大规模 RDMA 数据中心。 [来源:DCQCN.pdf,第 4–6、12 页]
- DCTCP:优点——ECN 精细反馈、低队列;缺点——慢启动导致突发场景劣势、主机实现(CPU 成本);适用——软实现数据中心 TCP。 [来源:DCQCN.pdf,第 2、11 页]
- QCN:优点——硬件反馈(L2);缺点——仅 L2,不能直接用于 IP 路由网络,需要 ASIC 改动。 [来源:DCQCN.pdf,第 4 页]
- TIMELY:优点——基于 RTT 的延迟信号,能进一步减小排队延迟;缺点——需要精确 RTT 测量,且未以降低主机 CPU 为目标。 [来源:DCQCN.pdf,第 12 页]
三条可执行启发(工程/研究)
- 在 100/400Gbps 迁移时优先验证 τ*(反馈延迟)与 NIC CNP 速率,重算 Timer、ByteCounter 与 K 值。 [来源:DCQCN.pdf,第 13 页]
- 在多瓶颈(parking-lot)场景下优先启用 RED-like 标记(P_max≈1%)以改善不公平问题,并用流体模型数值仿真验证。
- 将 CNP 与控制报文设置高优先级以减少反馈丢失/延迟,尤其在拥塞短时尖峰中有显著效果。 [来源:DCQCN.pdf,第 6 页]
互动环节(每主要知识点后都含 Q&A,见各节内)
总结 + 待办(研究/复现清单)
优先级与预估工时:
- 复现论文微基准(3机/1交换机)并验证流体模型拟合(优先级:高,工作量:3–5 天)。
- 在 20–80 台测试床上复现实验(incast、用户流混合),验证 PAUSE 统计(优先级:高,工作量:2–3 周)。
- 将参数迁移到不同 RTT(例如公有云跨机房 200μs)并重算 Timer/K/B(优先级:中,工作量:1 周 + 仿真)。
- 在 100Gbps 硬件上评估并重调 τ*/Timer/ByteCounter(优先级:中,工作量:2 周)。
- 扩展流体模型分析多瓶颈场景(parking lot)并自动搜索最优 RED 参数(优先级:中,工作量:2–3 周)。
- 与 TIMELY 在相同拓扑下对比延迟/吞吐(优先级:中,工作量:2 周)。
- 测试不同 packet loss 环境(0.01%–0.5%)下的恢复与应用层影响(优先级:中,工作量:1 周)。
- 将 DCQCN 与 TCP-Bolt/iWarp 做 CPU 与延迟比较(优先级:低,工作量:2 周)。
复现要点清单
- 使用支持 RED/ECN 与 PFC 的交换机(论文用 Arista 7050QX32 / Trident II)。[来源:DCQCN.pdf,第 2、6 页]
- 在 NIC 上实现 RP/NP 状态机:CNP 生成间隔 N≈50μs;RP 按式 (1)-(4) 更新 R_C/R_T/α。
- 初始参数:Timer=55μs,ByteCounter=10MB,K_max=200KB,K_min=5KB,P_max=1%,g=1/256。[来源:DCQCN.pdf,第 9 页(Figure 14)]
- 将 CNP 报文提升优先级以避免反馈延迟丢失。 [来源:DCQCN.pdf,第 6 页]
- 交换机 PFC 阈值使用动态 β 机制(论文示例 β=8)以保证 ECN 先于 PFC 触发;若使用静态上界会导致误触发。 [来源:DCQCN.pdf,第 6 页]
- 在部署前用流体模型数值解验证在目标 RTT/BW 下的稳态与收敛速度(τ* 的估计关键)。[来源:DCQCN.pdf,第 7–8 页]
- 测试包含多瓶颈与 incast 的拓扑(parking-lot、victim flow 场景)以验证 RED vs cut-off 的效果差异。 [来源:DCQCN.pdf,第 4、12 页]
- 保持无慢启动(flows start at line rate),因此必须启用 PFC 作为短时保护。
- 监测 PAUSE 帧计数与队列长度(e.g., egress queue counters)以诊断误配置(过多 PAUSE 表明参数需调整)。 [来源:DCQCN.pdf,第 9–10 页]
- 若网络有显著包丢(>0.1%),需评估 RDMA 层的丢包恢复(go-back-N)是否足够,否则可能导致吞吐急剧下降。 [来源:DCQCN.pdf,第 12 页]