Set a loss function
对于一个具体的图像识别问题,假设进行图像识别的类别总数已知,也即 closed vocabulary 问题。
由于分类总数变多,我们需要使用新的多分类函数与对应的损失函数。
任务定义:
将输入图像 x 分类到已知的 K 个类别之一
- 输入 x 为 RGB 图像。
- 标签 y 为 one-hot 向量。
- 输出为每类的预测分数(概率)。
注:实际上现在的 LLM 处理的已经是 open vocabulary 问题了,也即识别类别没有界限。
Softmax Activation
σ(z)i=∑j=1Kexp(βzj)exp(βzi),i=1,…,K
其中:
- z:原始输出,zi 为第 i 类的原始打分(logit)
- K:类别总数
- β:温度参数(默认为 1)
当 β→∞ 时 σ→one-hot,当 β→0 时 σ→Uniform。
一般地, 温度越高(β 越大)概率分布会越硬化,也即放大 logit 之间的差异。
注:
- one-hot 输出 01 向量,argmax 输出索引值
- 当 K=2 时 Softmax 与 Sigmoid 等价。也即:
σ([z0])1=Sigmoid(z)
Cross-Entropy
常用 NLL/CE:
LCE=−k=1∑KP(k)logQ(k)=H(P,Q)
其中 P(k) 为真实标签,Q(k) 为模型预测概率。
当真实标签是类别 k 的 one-hot 向量时,单个样本的损失即为:
ℓ=−logQ(k)
性质:
- LCE=H(P,Q)∈[0,+∞)
- 对于随机权重初始化下,初始计算出的损失约为 LCE(0)≈logK,其中 K 为类别总数。
事实上,随机初始化下首次预测应是公平的。
KL divergence
KL 散度用于比较两个分布 P 与 Q 之间的差异。
DKL(P∥Q)=x∈X∑P(x)logQ(x)P(x)=H(P,Q)−H(P)
其中 H(P,Q) 为交叉熵,H(P) 为熵。
性质:
- 非负性:DKL(P∥Q)≥0,等号当且仅当 P=Q
- 非对称性:DKL(P∥Q)=DKL(Q∥P)
- 不满足三角不等式
注:
- 衡量 Q 对 P 的描述能力差多少。故用于多分类损失函数时,取 P 为真实标签,Q 为模型预测概率。
- 对于固定的真实标签,H(P) 为常数。特殊地,one-hot 时 H(P)=0。故 KL 散度和 CE/NLL 是等价的。
Handle Underfitting
对于 Underfitting 的问题,解决的本质就是将模型复杂化,也即加深网络。为了避免加深网络时结构上的问题提出了 Normalization 和 Residual Link。
Normalization
对于深层神经网络,由于层与层之间的参数分布差异会随训练逐渐显著,而每次 backpropagation 使用相同的学习率,可能导致最终浅层网络与深层网络的 error 差异显著。
解决办法是进行 Batch Normalization。通过对 mini-batch 内每个激活做归一化来稳定训练、加速收敛,并在一定程度上起到正则化作用。
BatchNorm Layer in CNN
Train Mode:
设当前 mini-batch 为 B,包含 N=∣B∣ 个样本。
激活值 x∈RN×C×H×W,其中 C 为通道数,H,W 为高和宽。
对每个通道 c,在该 batch B 上的所有激活值集合大小为
m=N×H×W
则 B 中通道 c 的均值为:
μB,c=m1n=1∑Nh=1∑Hw=1∑Wxn,c,h,w
B 中通道 c 的方差为:
σB,c2=m1n=1∑Nh=1∑Hw=1∑W(xn,c,h,w−μB,c)2
归一化:
x^n,c,h,w=σB,c2+ϵxn,c,h,w−μB,c
线性变换:
yn,c,h,w=γcx^n,c,h,w+βc
其中 ϵ 为小常数,γc,βc 为需要学习的尺度和平移参数。
注:
- 共需学习 2C 个参数,注意参数是与 batch 无关的。
- BatchNorm 不改变维度。
- 在 backpropagation 时,上述 γc,βc,μ,σ 都会用到。
Eval Mode:
训练中维护每个通道的滑动平均均值和方差(running mean and variance):
μrun,c←ρ⋅μrun,c+(1−ρ)⋅μB,c
σrun,c2←ρ⋅σrun,c2+(1−ρ)⋅σB,c2
其中 ρ 为动量,通常取 0.9 或 0.99,初始时 μrun,c=0,σrun,c2=1。
验证/测试时:
x^n,c,h,w=σrun,c2+ϵxn,c,h,w−μrun,c
yn,c,h,w=γcx^n,c,h,w+βc
也即等价于一个 Linear Layer。
注:
- 一般只用于 hidden layers。output layer 不使用 BatchNorm,因为最后输出不应该假设服从 Gauss 分布。
- 一般先 BatchNorm 后 Activation,因为能够让激活函数工作在梯度最健康的区间。
- 有时候还会把 running variance 修正为无偏估计量,也即:
σrun,c2←ρ⋅σrun,c2+(1−ρ)⋅m−1mσB,c2
BatchNorm Layer in MLP
完全相同,只不过把对通道求均值变为了对特征维度求均值。
Train Mode:
设当前 mini-batch 为 B,包含 N=∣B∣ 个样本。
激活值 x∈RN×D,其中 D 为隐藏层神经元个数(特征维度)。
对每个特征维度 d,有:
μB,d=N1n=1∑Nxn,d
σB,d2=N1n=1∑N(xn,d−μB,d)2
x^n,d=σB,d2+ϵxn,d−μB,d
yn,d=γdx^n,d+βd
其中 ϵ 为小常数,γd,βd 为需要学习的尺度和平移参数。此时共需学习 2D 个参数,注意参数是与 batch 无关的。
Eval Mode:
训练中维护每个特征维度的 running mean and variance:
μrun,d←ρ⋅μrun,d+(1−ρ)⋅μB,d
σrun,d2←ρ⋅σrun,d2+(1−ρ)⋅σB,d2
其中 ρ 为动量,通常取 0.9 或 0.99,初始时 μrun,d=0,σrun,d2=1。
验证/测试时:
x^n,d=σrun,d2+ϵxn,d−μrun,d
yn,d=γdx^n,d+βd
BatchNorm Pros
- BatchNorm 最初的想法是减少 internal covariate shift(内部协变量偏移),也即网络中间层的输入分布在训练过程中不断漂移,导致训练困难。
而 BatchNorm 归一化了每层输入的分布,减少了这种 shift
- 后续研究认为更加重要的是 BatchNorm 可以平滑化 loss landscape,也即使得损失函数更加平滑,
从而使梯度方向更一致、尺度更稳定,允许更大的学习率、更快收敛。
- 存在 batch dependence,也即同一 batch 中的样本会相互影响。从而引入了微小的 batch noise 带来轻微的正则化。
BatchNorm Cons
- 也是由于 batch dependence 的存在,当 batch size 很小时,batch mean / variance 不稳定,
并且训练时使用 batch mean / variance,验证/测试时使用 running mean / variance,导致性能不一致。
- 本质上 BatchNorm 假设了所有 N×H×W 个数值独立同分布,从而对分布高度相关的实例不适用。
Other Normalizations
- LayerNorm:按单个样本做归一化,常用于 RNN / Transformer。
- InstanceNorm:按单个样本的单个通道做归一化,常用于具有明显样本风格的图像工作。
- GroupNorm:把通道分组后在组内归一化,适合小 batch 或样本高度相关场景。
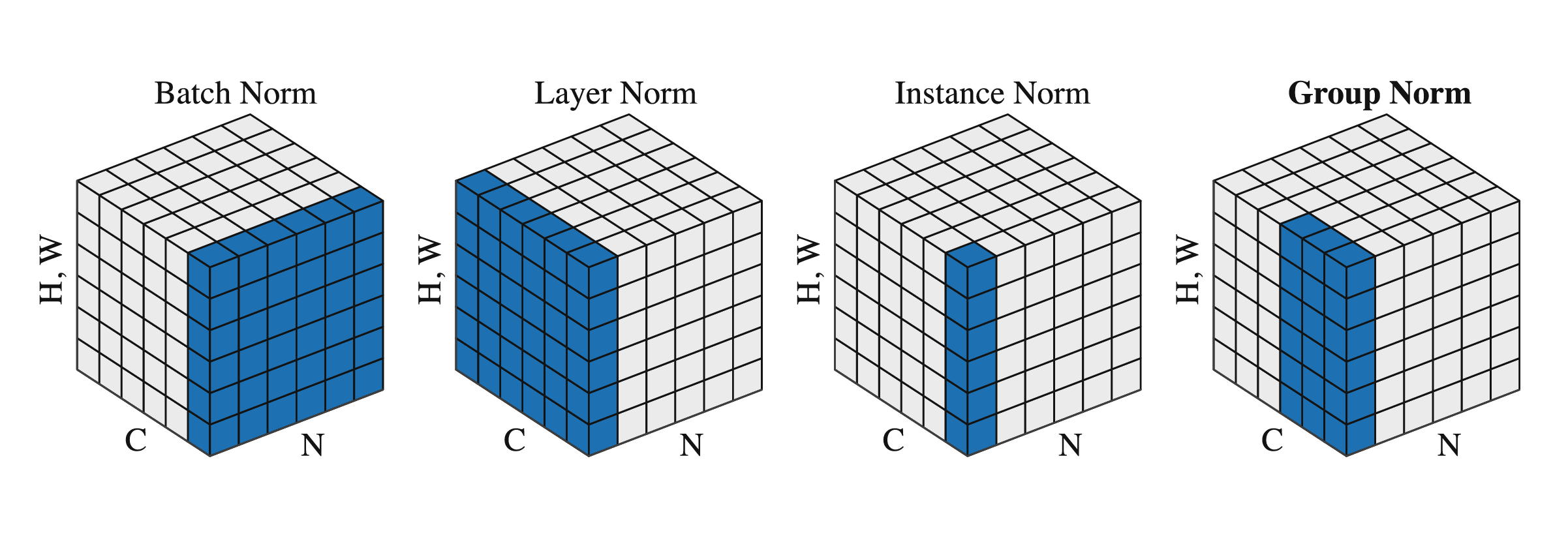 图 1:Normalizations,每个都是对蓝色区域进行归一化
图 1:Normalizations,每个都是对蓝色区域进行归一化
credit: Wu, Y., & He, K. (2018). Group Normalization.
注:
- 蓝色覆盖 N 的维度就不会有 batch dependence,故后三者均没有。
- 实际上,实验证明 BatchNorm 的问题在 batch size 足够大时影响很小,并且效果也是最好的。当资源有限时,使用 GroupNorm 是一种权宜之计。
Residual Link
也称为 Skip Link。
当加深神经网络时:
- backpropagation 视角:越底层的梯度计算链越长,数值越难控制,训练效果越差;
- forward 视角:底层的模型差,顶层的模型好也没用。
核心思想:
希望在已训练好的神经网络上继续加深,理论上不会变的更差。
不妨学习残差(output - input),那么当加深无益时,只需让 Residual block 趋于 0 即可,这比 Plain layers 学习一个恒等映射容易的多。
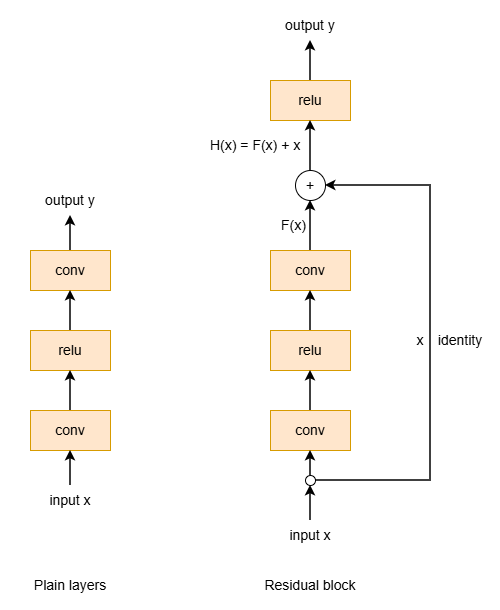 图 2:Residual Link
图 2:Residual Link
Pros:
- backpropagation 视角:Residual Link 提供了 bypass,可以缓解梯度消失或爆炸。
- loss landscape 视角:网络加深时,loss landscape 会逐渐远离 convex(凸性),变得 chaotic(混沌),显然更容易被 local minimal 截胡。
增加 Residual Link 可以使得 loss landscape 变得更平坦。
Handle Overfitting
本质上是把数据中的噪声也当作模型的一部分学习了。
所以我们应当让 data variability 与 model capacity 匹配,要么适当降低模型复杂度,要么想办法增加数据量。
Early Stopping
当验证集的 accuracy 持续下降时就提前停止训练。打不过就放弃吧qwq
Data Augmentation
通过数据增强的方式,增大 data variability。
 图 3:常见的数据增强手段
图 3:常见的数据增强手段
注:
DA 的 Magnitude(强度)很重要。
- 过强的 DA 可能会造成 error,对模型有害无益,
- 过弱则作用有限。
通常通过超参数调优或人工检验确定。人工检验的标准就是输入数据人脑能否正确识别。
Regularization
通过对权重的限制,降低 model capacity。
常见类型:
Lreg=Lmain+R(θ)
其中 R(θ) 的常见形式有:
- Ridge Regression / L2 regularization:
R(θ)=2λ∥W∥22=2λlayer L∑i,j,…∑(Wi,j,…(L))2
其中 λ 被称为 weight decay,因为对权重求梯度时:
∂W∂Lreg=∂W∂Lmain+λW
从而在更新权重时:
Wt+1=Wt−α∂W∂Lreg=Wt−α(∂W∂Lmain+λWt)=恒定权重衰减(1−αλ)Wt−α∂W∂Lmain
可见权重的衰减比例为 αλ。
- Lasso Regression / L1 regularization:
R(θ)=λ∥W∥1=λlayer L∑i,j,…∑∣Wi,j,…(L)∣
对权重求次梯度时:
∂W∂Lreg=∂W∂Lmain+λ⋅sign(W)
其中 sign(⋅) 按 element wise 理解。从而在更新权重时:
Wt+1=Wt−α(∂W∂Lmain+λ⋅sign(Wt))=Wt−α∂W∂Lmain−向零推动的恒定步长αλ⋅sign(Wt)
可见 L1 regularization 会以恒定步长 αλ 向零推动权重,使不重要的权重归零,产生稀疏解。
- Elastic net / L1 + L2:
R(θ)=λ1∥W∥1+2λ2∥W∥22=layer L∑i,j,…∑(λ1∣Wi,j,…(L)∣+2λ2(Wi,j,…(L))2)
显然其同时具有 L2 的权重衰减效应和 L1 的稀疏化效应。
注:
- 使用 L1 时不可导,但是可以使用次梯度进行最优化。
- θ 包含了所有可学习的参数,比如权重 W,偏置 b,BN 层的 γ,β 等等。而我们 regularization 时一般只使用权重 W。
Dropout
通过丢弃(置零)一些神经元输出的激活值,降低 model capacity。
Train Mode:
对每个神经元的输出,以概率 p 将其置 0,以概率 1−p 保留。
也即对某一层的输出向量 a=(a1,a2,…,an)⊤,采样同维度随机向量:
r∼Bernoulli(1−p)n
输出:
y=r⊙a
其中 ⊙ 为逐元素乘。
由于每次前向传播都重新独立采样,相当于同时训练大量不同的随机子网络。
可以打破神经元之间的co-adaptation(共适应),防止网络过度依赖某些特定的连接。
Eval Mode:
使用全部神经元,不做随机丢弃,以利用完整模型。
但直接这样,train 输出期望只有 eval 输出期望的 1−p,故需修正。
| 方法 | train mode | eval mode |
|---|
| Standard Dropout | 直接置零 | 输出乘以 (1−p) |
| Inverted Dropout | 保留的输出除以 (1−p) | 无需任何操作 |
Inverted Dropout 的优势在于测试阶段代码更简洁、推理更快,因此现代框架通常默认采用这种方式。
注:
Dropout 对大型 FC 较有效,Conv 层上通常不用 Dropout 而用 BN。
BatchNorm
BatchNorm 也起到一定正则化效果。
- BN 约束激活前的输出服从高斯分布,降低了 model capacity。
- BN 的均值和方差是基于 mini-batch 的估计量,其中引入了 Batch noise,可以防止网络过度依赖某些特定的连接。
所以在 CNN 中,由于 BN 的存在,我们可以不再依赖 Dropout。