Classification Backbones
Conceptions
Backbone(主干网络)指用于提取图像通用特征的 CNN 模块,后续可以接负责具体任务(如分类)的 head。
从 ImageNet 的优胜模型演化我们可以看出 Backbone 的一些 implementation details。
历史的顺序为 AlexNet、VGG、ResNet 等。
Backbone 性能分析:
- Expressivity/Capacity:模型能表示函数的复杂程度。
- Fitness for task:对细粒度识别需要既有细节又有上下文。
- Optimization properties:可训练性。
- Cost:计算量、参数量、内存占用和推理延迟。
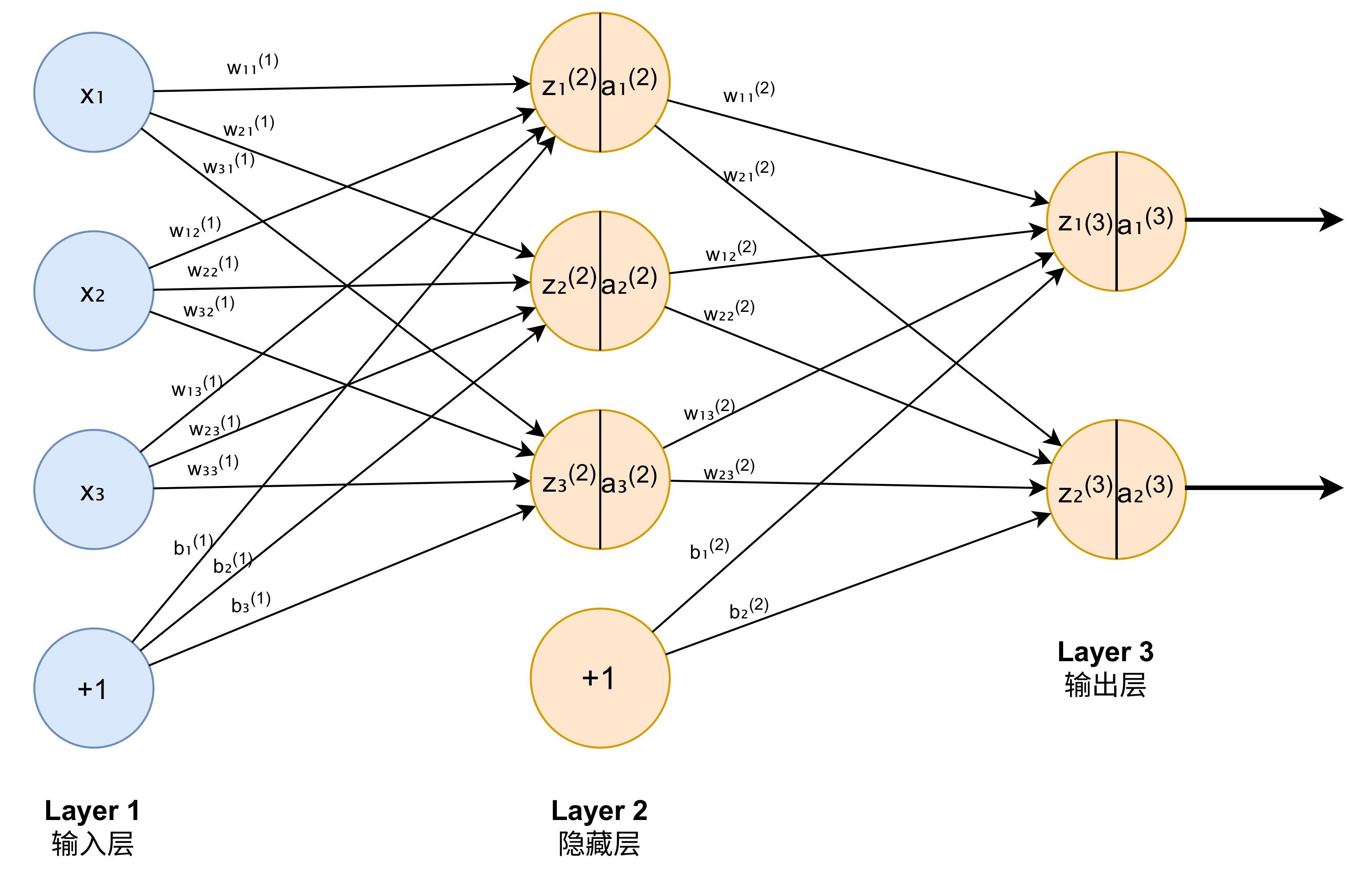 图 1:神经网络示意图,其中有竖线的橙色圆圈代表 neurons,有向边代表 params。neurons 对应了内存占用,params 对应了参数量
图 1:神经网络示意图,其中有竖线的橙色圆圈代表 neurons,有向边代表 params。neurons 对应了内存占用,params 对应了参数量
From AlexNet to VGG
VGG 相比 AlexNet 使用了更深的层数和更小的 filter。
感受野:
网络中影响一个神经元输出的输入像素范围称为该神经元的 Receptive Field(感受野)。
感受野的递推公式:
设第 ℓ 层 kernel 大小为 kℓ,stride 为 sℓ,receptive field 为 fℓ。
注意第 ℓ 层的 kernel 作用于第 ℓ 层的输入,输出第 ℓ+1 层的特征。
定义第 ℓ 层的 jump 为 jℓ,也即第 ℓ 层相邻激活对应输入像素的间距。则:
jℓfℓ=sℓ−1⋅jℓ−1=i=1∏ℓ−1si,j1=1=fℓ−1+(kℓ−1−1)⋅jℓ−1,f1=1
证明:
jump 的递推公式是显然的。
对于 receptive field,考虑第 ℓ 层的一个神经元,它可以感受到第 ℓ−1 层中跨度 kℓ−1 个神经元。
它能感受到的第 ℓ−1 层神经元的所有感受野堆叠形成的区域就是它自身的感受野。
这 kℓ−1 个神经元各自的感受野在输入层上会有重叠,如下图所示。故重叠大小为:
overlap=fℓ−1−jℓ−1
从而整体感受野长度为:
fℓ=fℓ−1+(kℓ−1−1)⋅jℓ−1
当然,这里面还需确保感受野确实是重叠的,或者说感受野之间没有空隙。也即验证:
fℓ≥jℓ
代数化简得只需满足 kℓ≥sℓ,上式即自动满足。
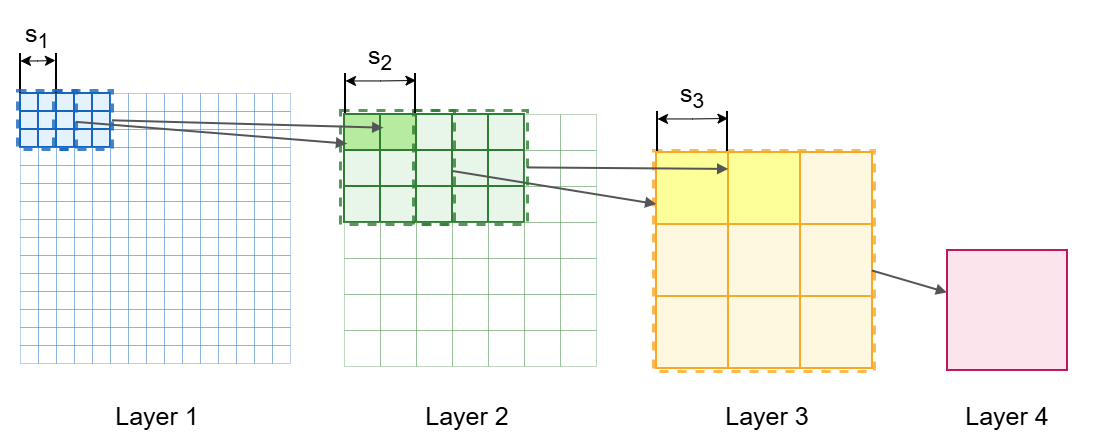 图 2:感受野的递推公式 1,Conv 层示例,虚线框代表 kernel
图 2:感受野的递推公式 1,Conv 层示例,虚线框代表 kernel
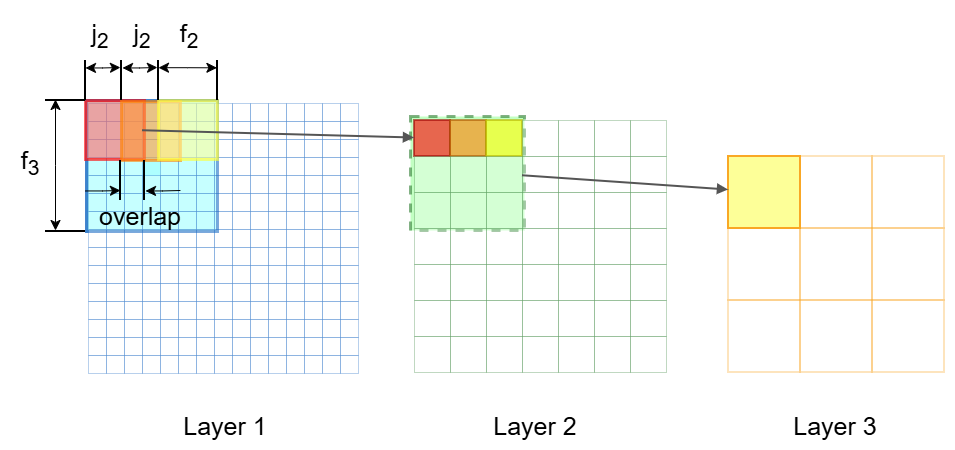 图 3:感受野的递推公式 2,计算 f3,实线框代表 field
图 3:感受野的递推公式 2,计算 f3,实线框代表 field
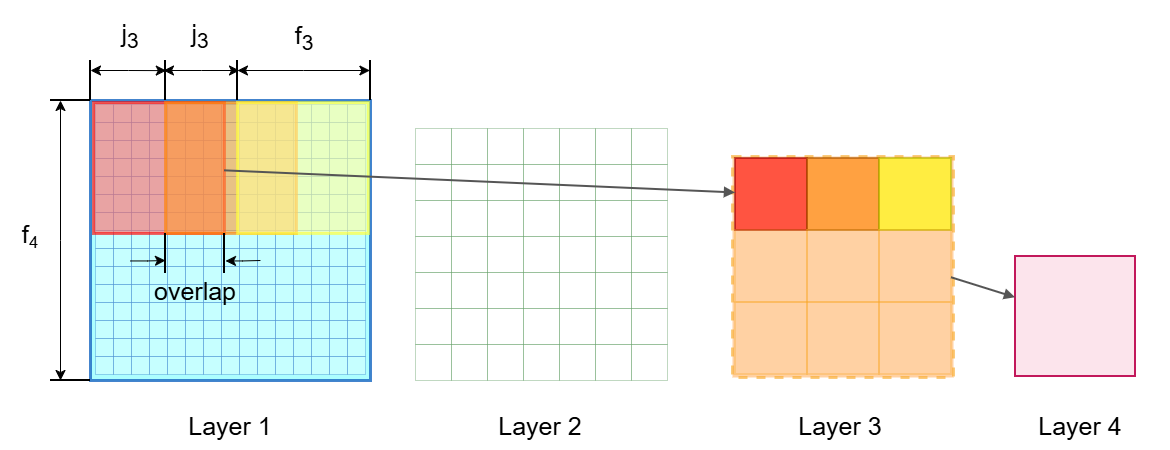 图 4:感受野的递推公式 3,计算 f4,实线框代表 field
图 4:感受野的递推公式 3,计算 f4,实线框代表 field
smaller kernel & deeper net 的好处:
- 多层小 filter 与单层大 filter 可以获得相同的感受野。
- 层数越多,激活越多,nonlinear 越强,capacity 越强。
- 参数更少。
举例来说,取 stride 均为 1,且输入输出通道始终为 C。
则 3 层 3×3 Conv 与 1 层 7×7 Conv 感受野相同。
但是前者有 3 次激活,只需 3⋅(32C2) 参数;
后者只有 1 次激活,需要 72C2 参数。
注:
感受野不是越大越好。太大可能带来过多噪声,而太小则无法捕获全局上下文。
From VGG to ResNet
ResNet 相比 VGG 网络深度有了显著的提升,主要是因为使用了 Residual Block。
有关内容见前述笔记 Residual Link。
同时 ResNet 还引入了 bottleneck(瓶颈层)。
Bottleneck 的核心是先提炼关键信息,只在关键信息上做昂贵的大卷积核运算,从而减少参数量。
具体来说:
- 先用 64 个 1×1 的 kernel 把 256 维特征压缩到 64 维子空间。
- 然后用 64 个 3×3 的 kernel 进行空间特征提取,
- 最后再用 256 个 1×1 的 kernel 升维回 256 维。
下图中两种 block 均完成了 28×28×256 到 28×28×256 的映射,对比两者的参数量:
- Basic Block:2(32×2562)≈1.18M
- Bottleneck:12×256×64+32×642+12×64×256≈70K
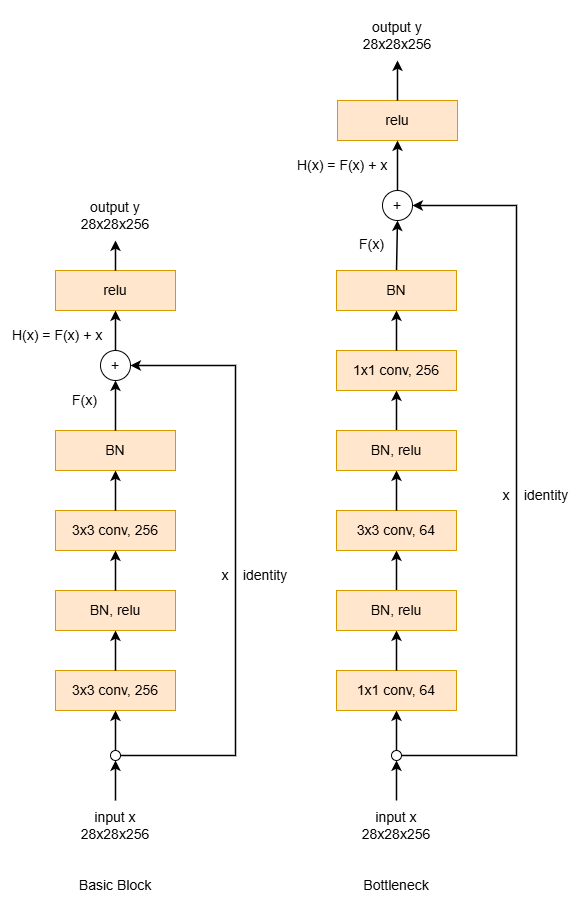 图 5:Bottleneck
图 5:Bottleneck
Beyond ResNet
ResNet 对于 CNN 的开发已基本完善。不过后续还有诸多变体。
-
SENet:通道注意力,通过学习通道权重来加强重要通道的特征。
-
DenseNet:密集连接,每层接收前面所有层的特征并 concatenate 为后续输入。
-
MobileNet:深度可分离卷积(Depthwise Separable Convolution),将标准卷积拆分为两步,降低计算成本,使 CNN 可在移动端实时运行。
本质上是把对空间的混合和对通道的混合解耦开了。
-
标准卷积(图 a):
对于 H×W×M 的输入,要得到 N 个输出通道,每个输出通道需要一组卷积核。
每组包含 M 个 Dk×Dk 的 kernel,分别对应 M 个输入通道;卷积结果在通道维度上求和,得到一个输出通道。因此总共需要 N 组。
计算量为 Dk2⋅M⋅N⋅H⋅W。
-
MobileNet(图 b-c):
将上述过程解耦为两步。
-
Depthwise 卷积(图 b):
对 H×W×M 的输入,每个输入通道单独做空间卷积。
每个通道只用 1 个 Dk×Dk 的 kernel,共需 M 个 kernel。
此时输出仍为 H×W×M。
计算量为 Dk2⋅M⋅H⋅W。
-
Pointwise 卷积(图 c):
使用 1×1 卷积将 M 个通道混合为 N 个输出通道。
每个输出通道需要 M 个 1×1 的 kernel,共需 N 组。
计算量为 12⋅M⋅N⋅H⋅W。
当通道数 N 较大时,计算量约为标准卷积的 1/N,精度损失却很小。
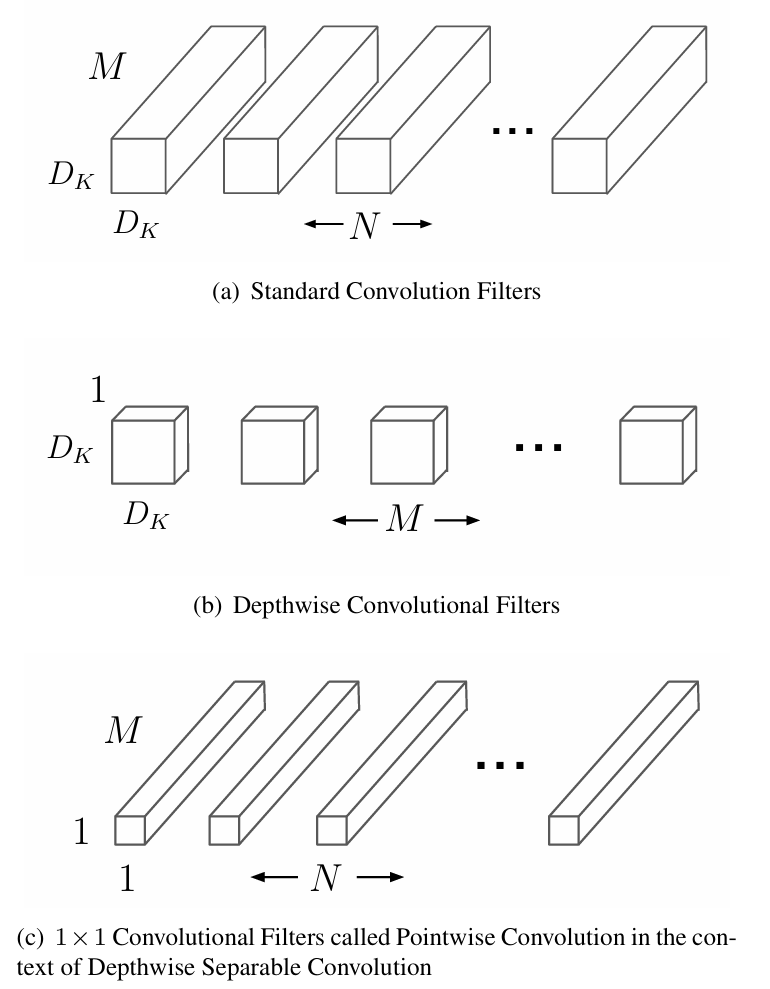 图 6:深度可分离卷积
图 6:深度可分离卷积
credit: Howard A. G., et al. (2017). MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications.
- NAS(Neural Architecture Search):使用学习算法自动搜索网络结构。
Segmentation
Defination
图像分割是将图像中属于不同语义/实例的像素分组的任务。也即 Pixel-based Classification。
- Semantic Segmentation:语义分割,逐像素预测类别,不区分同类不同实例。
- Instance Segmentation:实例分割,逐像素预测类别,且区分同类不同实例。
- Semantic Instance Segmentation:前两者的结合,对前景物体(things)进行实例分割,对背景(stuff)只进行语义分类。
FCN
全卷积网络(Fully Convolution Network)可以接受任意输入尺寸,并输出与输入同尺寸的预测图。
但是图像尺寸实在是太大了,我们需要使用 Bottleneck 思想,采用以下 Auto-Encoder 框架:
-
Encoder:
执行 downsampling,内存占用和参数量更小,感受野更大。
设输入图像为 x∈RC0×H0×W0,下采样模块共 L 层,sℓ 为第 ℓ 层的下采样因子(如 Conv 的 stride)。
则总下采样因子为:
D=ℓ=1∏Lsℓ
从而得到瓶颈处的空间尺寸:
HL=⌊DH0⌋,WL=⌊DW0⌋
整个 Encoder 可视为一个参数化映射 Eθ,参数集合为 θ,满足:
Eθ:X→Z,x↦Z=Eθ(x)∈RCL×HL×WL
其中 CL 为瓶颈处通道数。
-
Decoder:
执行 upsampling,将瓶颈特征恢复至原始尺寸。
设上采样模块共 L′ 层,第 k 层的上采样因子(如 ConvTranspose 的 stride)为 tk。
则总上采样因子为:
U=k=1∏L′tk
为保证输出尺寸与输入一致,通常有 U=D,且:
H0≈U⋅HL,W0≈U⋅WL
整个 Decoder 可视为一个参数化映射 Dϕ,参数集合为 ϕ。
当用于图像重构时,记为:
Dϕ:Z→X^,Z↦x^=Dϕ(Z)∈RC0×H0×W0
其中 x^=Dϕ(Eθ(x)) 为重构输出,C0 为输出通道数(如 RGB 图像为 3)。
当用于语义分割时,记为:
Dϕ:Z→Y^,Z↦y^=Dϕ(Z)∈RK×H0×W0
其中 K 为类别数,y^c,i,j 表示位置 (i,j) 属于类别 c 的预测概率。
-
Loss Function:
取决于具体的任务。
对于图像重构:
Lrebuild(θ,ϕ)=Ex∼pdata[∥x−x^∥22]
对于语义分割:
Lseg(θ,ϕ)=−H0W01i=1∑H0j=1∑W0c=1∑Kyc,i,jlogy^c,i,j
其中 yc,i,j∈{0,1} 为位置 (i,j) 的 one-hot 真实标签,y^c,i,j∈[0,1] 为模型预测概率。
Bottleneck Pros:
- 内存占用更低,对于高分辨率图像来说很重要。
- 在更小特征图上进行 conv,等效感受野更大,能以更低 cost 捕获更大范围 context。
注:
本质上日常生活中的图像都是内嵌于高维空间的低维流形(minifold)。
通过压缩可以保留重要语义,丢弃冗余信息,便于进一步语义分割。
Non-learnable Upsampling
- Bilinear:双线性插值。目标像素在源图像中计算坐标,然后做插值。
- Nearest Neighbor Unpooling:最近邻上采样。将每个像素放大为 r×r 的 block,block 内都填充像素值,其中 r 为上采样因子。
- Bed of Nails Unpooling:零填充上采样。将每个像素放大为 r×r 的 block,block 左上角填充像素值,其余为 0,其中 r 为上采样因子。
- Max Unpooling:与 Max Pooling 配对使用。
Downsampling 时记录每个 pooling window 中最大值的位置索引;
Upsampling 时,将每个输入值放回原来的位置,其余位置置 0。
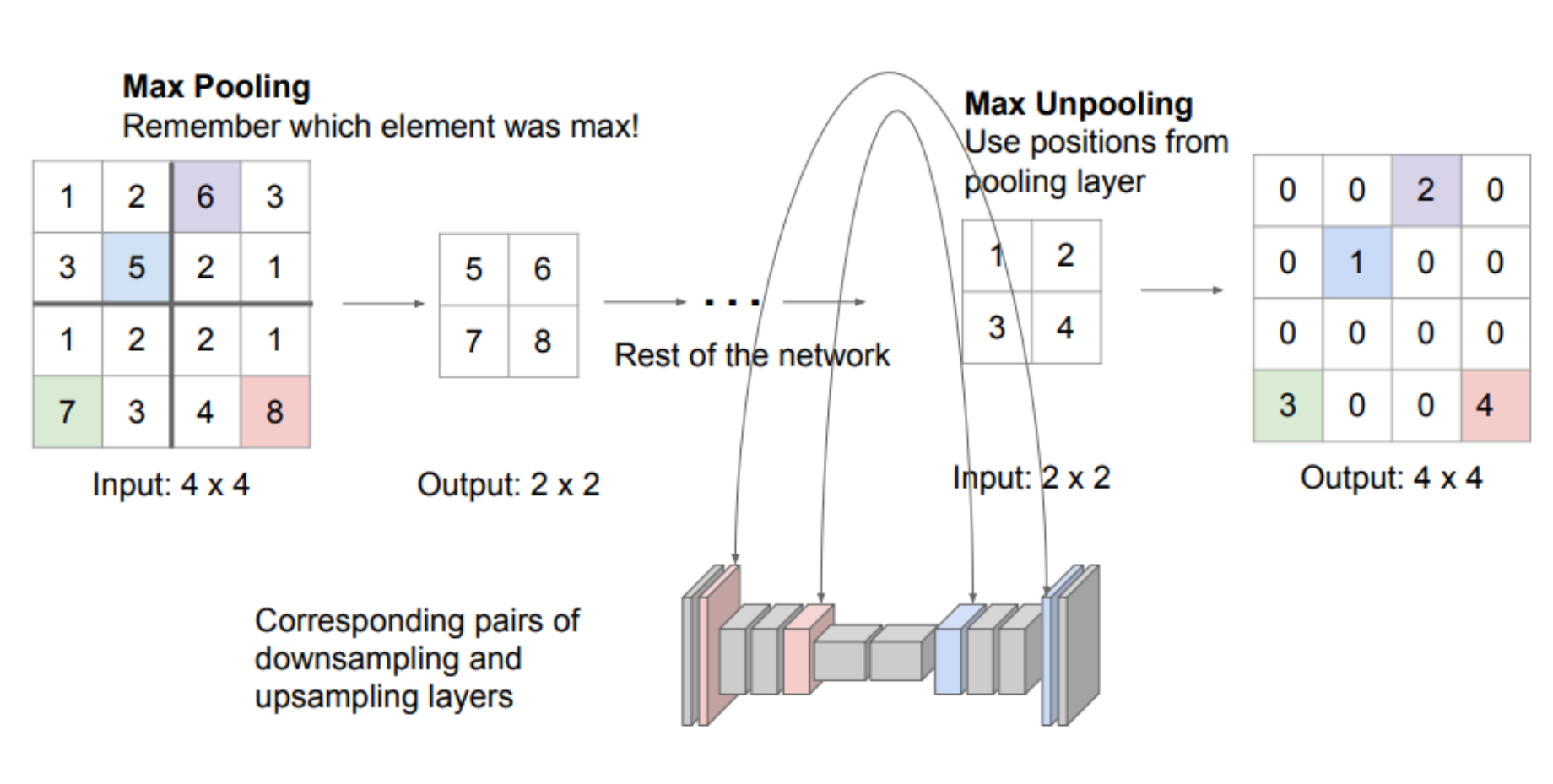 图 7:Max Unpooling
图 7:Max Unpooling
credit: PKU Intro to CV Slides
Learnable Upsampling
Transposed Convolution(转置卷积)。
部分文献中也称为 Deconvolution(反卷积),但数学上的 deconvolution 定义为卷积的逆运算,而转置卷积并不保证恢复原始输入,因此并不合适。
定义:
普通卷积可展开为稀疏的 Toeplitz 矩阵 C,使得
y=w∗x=Cx
转置卷积即在该矩阵表示下,使用 C⊤ 进行乘法:
x=w∗⊤y=C⊤y
由于普通卷积的反向传播时有:
∂x∂L=C⊤∂y∂L
转置卷积的前向传播恰好对应上述 C⊤ 的乘法操作。因此它常被描述为普通卷积在 backpropagation 时的梯度运算。
等价性:
转置卷积可以用普通卷积来模拟。
考虑一个普通卷积:
- 输入尺寸为 hin×win
- 参数为 kernel k、stride s、padding p
- 输出尺寸为 hout×wout
与之对应的转置卷积与之共享同一组参数 (k,s,p),且尺寸满足:
hin′=hout,win′=wout,hout′=hinwout′=win
概念上,该转置卷积等价于对输入 hin′×win′ 执行以下普通卷积:
- Stretching:在输入像素之间插入 s−1 个零;
- Surrounding padding:四周填充 k−p−1 个零;
- Additional padding:若 hin+2p−k 不能被 s 整除,还需在输入的 bottom 和 right 额外补 a 个零,其中
a=(hin+2p−k)mods,a∈{0,1,…,s−1}
这里 hin 即转置卷积期望的输出尺寸 hout′;
- Convolution:使用 unit stride s′=1 和 kernel k 进行卷积。
转置卷积的输出尺寸公式为:
hout′wout′=s(hin′−1)+a+k−2p=s(win′−1)+a+k−2p
下面是一些图示:
- 图中下方蓝色的是执行了 Stretching、Surrounding padding 和 Additional padding 后的图像。
- 图中上方是使用等价 convolution 后,也即 Transposed Convolution 后得到的上采样图像。
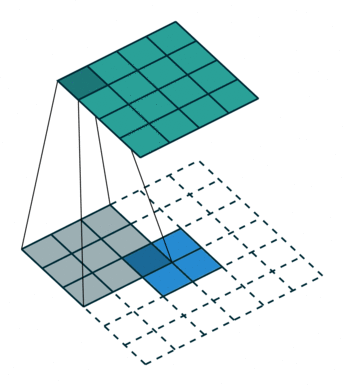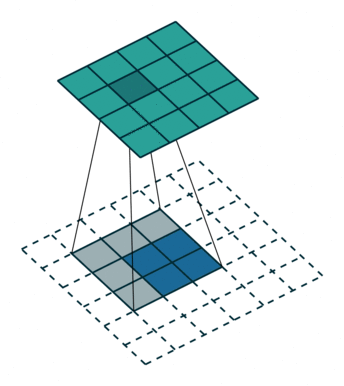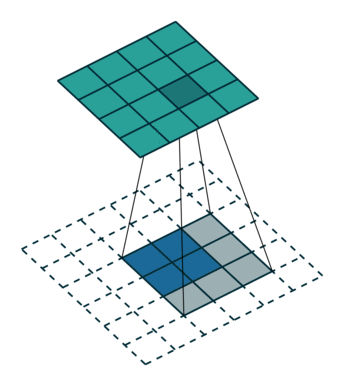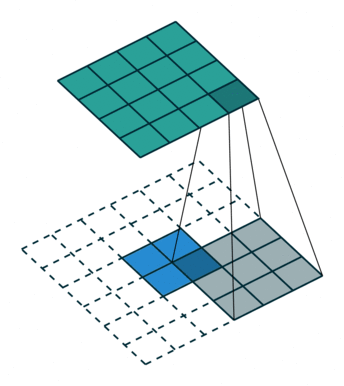 图 8:h'_in=2, h'_out=4, k=3, s=1, p=0
图 8:h'_in=2, h'_out=4, k=3, s=1, p=0
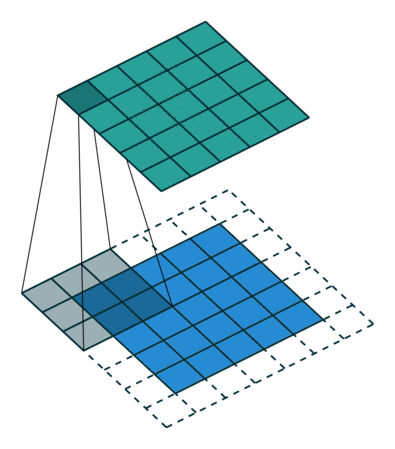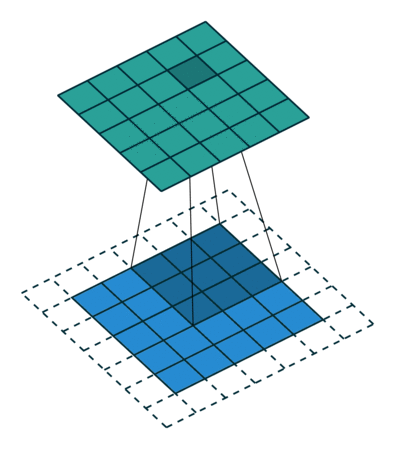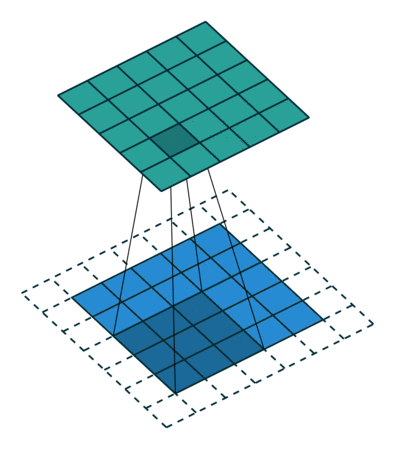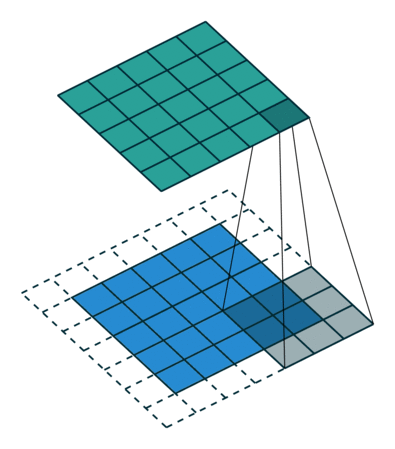 图 9:same padding, h'_in=5, h'_out=5, k=3, s=1, p=(k-1)/2
图 9:same padding, h'_in=5, h'_out=5, k=3, s=1, p=(k-1)/2
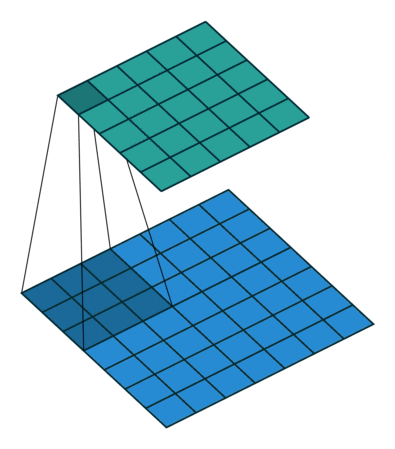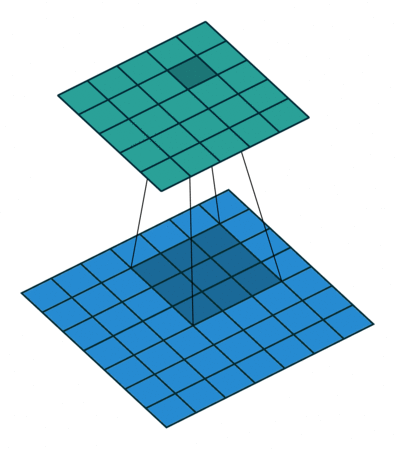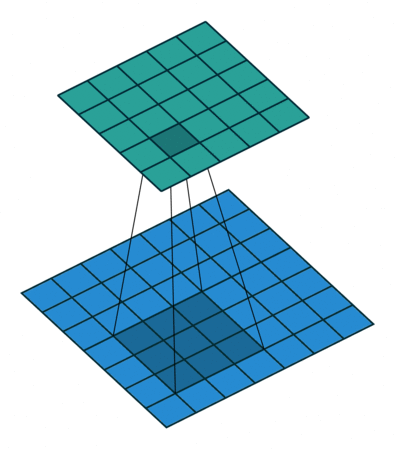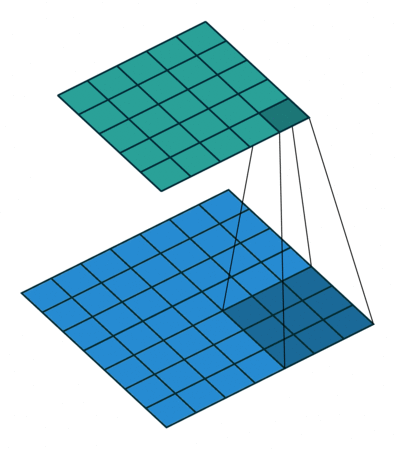 图 10:full padding, h'_in=7, h'_out=5, k=3, s=1, p=k-1
图 10:full padding, h'_in=7, h'_out=5, k=3, s=1, p=k-1
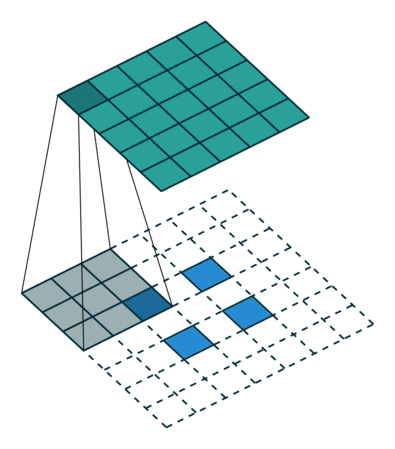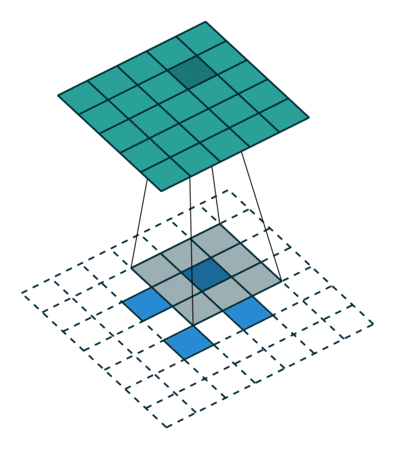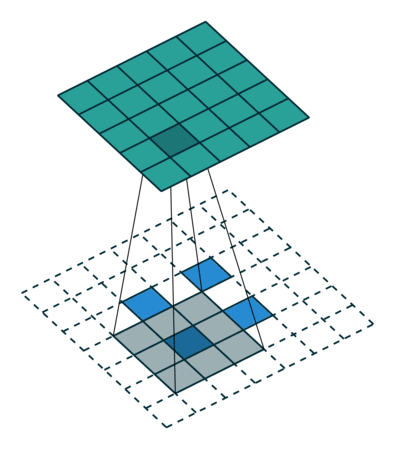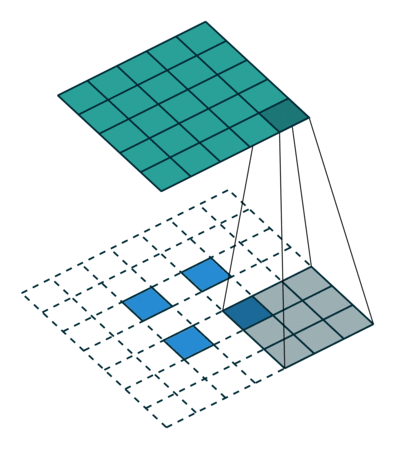 图 11:h'_in=2, h'_out=5, k=3, s=2, p=0
图 11:h'_in=2, h'_out=5, k=3, s=2, p=0
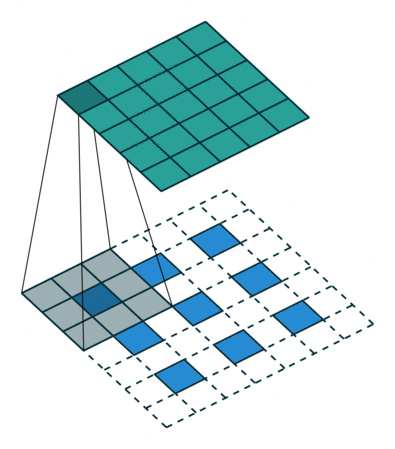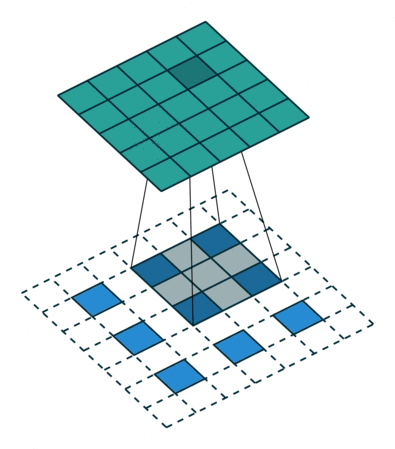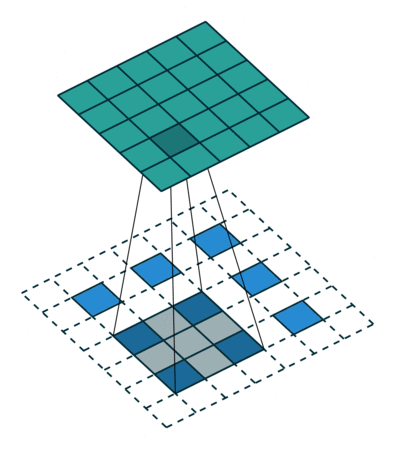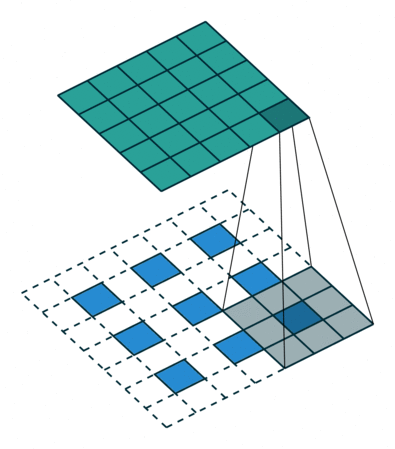 图 12:h'_in=3, h'_out=5, k=3, s=2, p=1
图 12:h'_in=3, h'_out=5, k=3, s=2, p=1
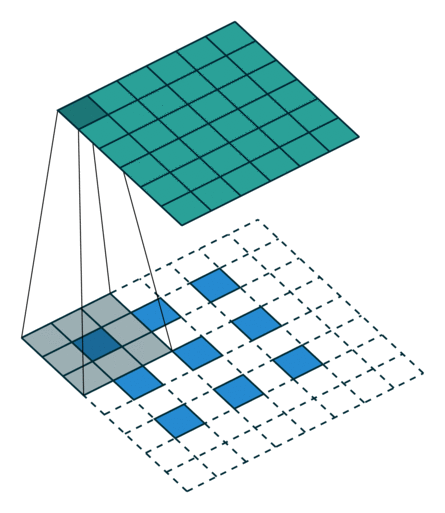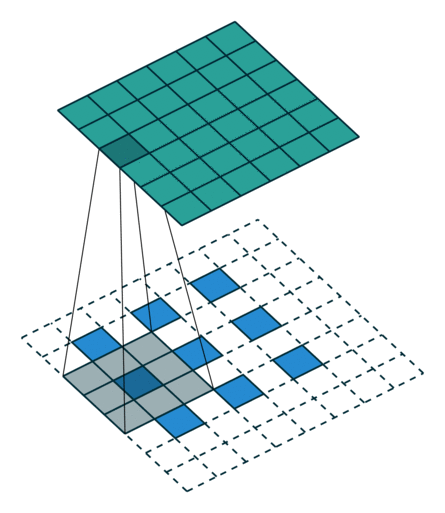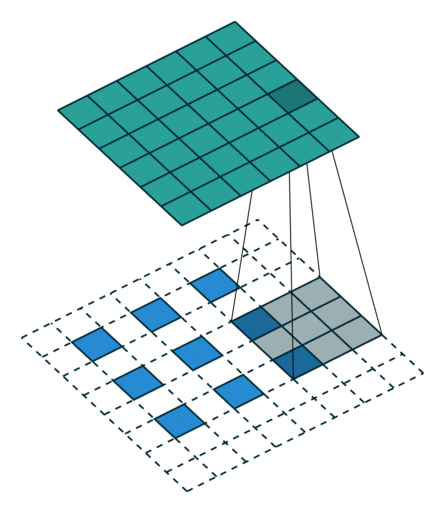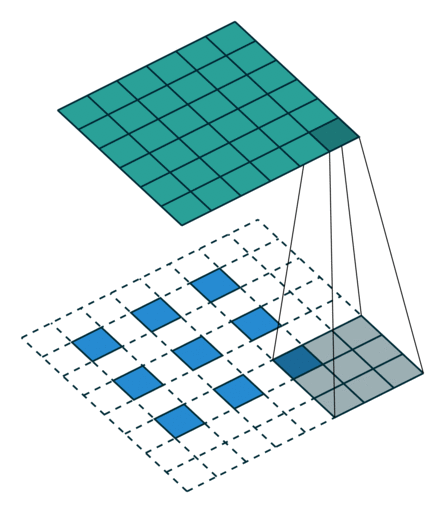 图 13:h'_in=3, h'_out=6, k=3, s=2, p=1
图 13:h'_in=3, h'_out=6, k=3, s=2, p=1
注:这只是概念上等价的示意方法。实际软件实现不会真的插入大量零再做乘法,因为那样会产生大量无效的零乘运算,效率极低。
credit:
Checkerboard Artifacts:
转置卷积的一个已知缺陷是:当 kernel 尺寸 k 不能被 stride s 整除时,kernel 在输出空间上的重叠区域不均匀,导致叠加后累积激活强度不一致,产生周期性的棋盘格伪影。
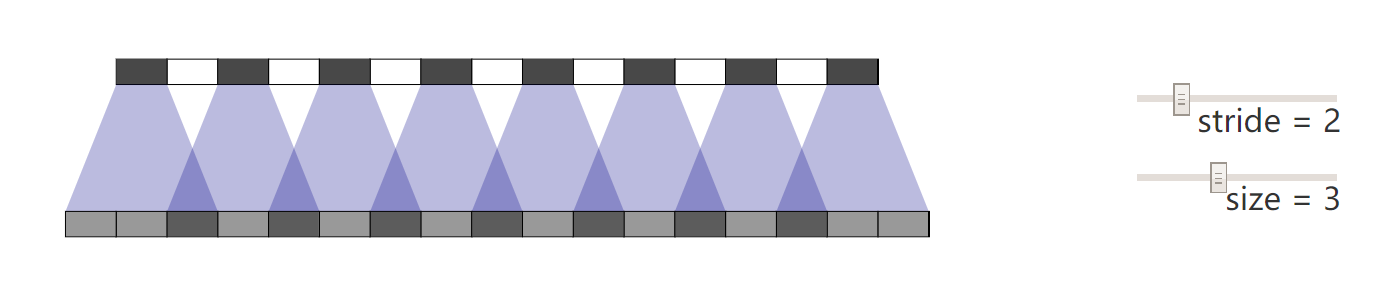 图 14:一维棋盘格伪影
图 14:一维棋盘格伪影
 图 15:stride 整除 kernel 时没有伪影
图 15:stride 整除 kernel 时没有伪影
 图 16:二维棋盘格伪影
图 16:二维棋盘格伪影
替代方案:
- PixelShuffle / Sub-pixel Convolution:用一些神秘的手段天然避免了棋盘格问题。
- Resize-Conv:先使用非学习型插值进行上采样,再用普通 3×3 卷积微调。
UNet
Network Architecture Design 的两个核心:
- Information Sufficiency:是否具备支持任务完成的充足信息。
例如,分类任务需要足够大的感受野覆盖目标整体;分割任务则要求保留逐像素的空间定位信息。
- Optimization Feasibility:是否利于优化。
通常任务越复杂,网络的 capacity 要求越高,收敛难度也随之增大。
FCN 的问题在于信息流单向串行,所以 Bottleneck 处必须同时承载global context与per-pixel spatial,这使得 Bottleneck 承担了过度复杂的任务,优化困难。
UNet 在 Auto-Encoder 框架中加入 Skip Link,把 Encoder 中对应分辨率的特征直接拼接到 Decoder 的对应层。
从而 Bottleneck 只需负责 global context,Skip Link 补充 per-pixel spatial,减轻了 Bottleneck 的负担。
注意此处的 Skip Link 执行的是 Concatenation 而非 Addition。
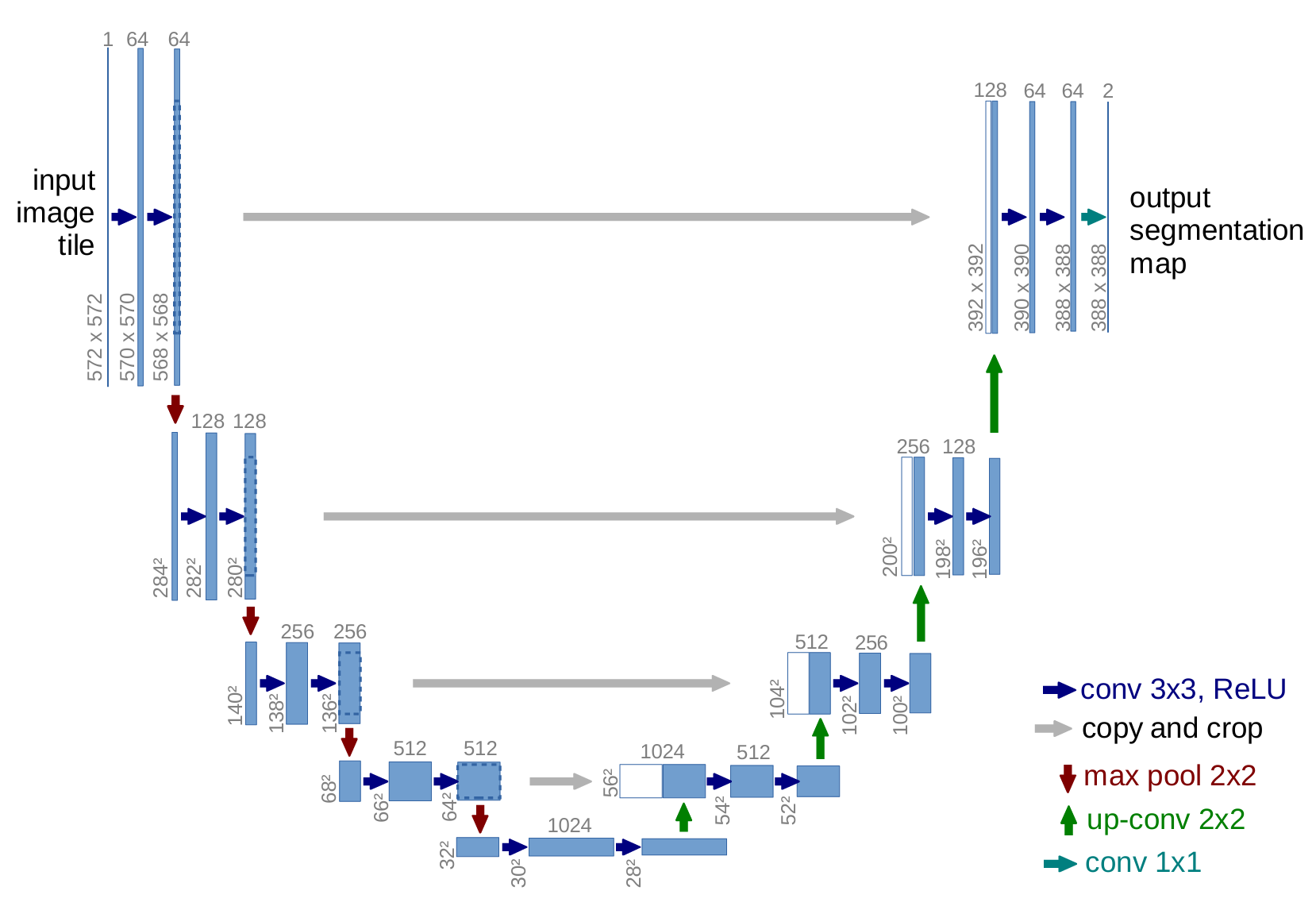 图 17:UNet 架构
图 17:UNet 架构
credit: Ronneberger O., et al. U-Net: Convolutional Networks for Biomedical Image Segmentation
Evaluation Metrics
Pixel Accuracy:
Accuracy=TP+TN+FP+FNTP+TN
问题在于当 positive 类占比极小时,准确率由 TN 主导,此时模型即使完全不预测 positive 类也有接近 100% 的准确率。
IoU:
Intersection over Union,交并比,可用于评估某一类的分割能力。
IoU=∣Prediction∪GroundTruth∣∣Prediction∩GroundTruth∣
其中 Prediction 为预测掩码,GroundTruth 为真值掩码。
二分类问题中即为:
IoU=TP+FP+FNTP
注:本质上只要是两个集合,就可以用 IoU 计算相似度。
mIoU:
mean IoU 可用于评估对多类的整体分隔能力,也即对每个类计算 IoU,再取平均。
mIoU=K1k=1∑KIoUk
其中 K 为总类数。
注:
对类别不平衡问题,mIoU 能公平考虑每个类的分割性能;
Soft IoU Loss
本质上 train objection 为 Loss function,而 test objection 为 Evaluation metrics,两者往往不一致:
- Loss Function:作为训练目标,必须可导
- Evaluation Metrics:真实任务需求,可能不可导
我们希望构造合适的 Loss function 以对齐 Evaluation metrics,从而缩小 surrogate gap。
Soft IoU Loss:
标准 IoU 基于离散的二值掩码,不可导。Soft IoU Loss 将其连续化。
设网络经 Sigmoid 或 Softmax 输出的概率图为 p,对应 one-hot 标签为 y。定义软交集与软并集:
Soft IntersectionSoft Union=i∑piyi=1−i∑(1−pi)⋅(1−yi)=i∑(pi+yi−piyi)
则 Soft IoU 为:
Soft IoU=SoftUnionSoft Intersection=∑ipi+∑iyi−∑ipiyi∑ipiyi
实现中通常加入平滑项 ϵ 防止除零,并取 1−Soft IoU 作为 Loss:
LIoU=1−∑ipi+∑iyi−∑ipiyi+ϵ∑ipiyi+ϵ
对于多类分割,可逐类取均值计算 mIoU Loss:
LmIoU=1−K1k=1∑K∑ipk,i+∑iyk,i−∑ipk,iyk,i+ϵ∑ipk,iyk,i+ϵ